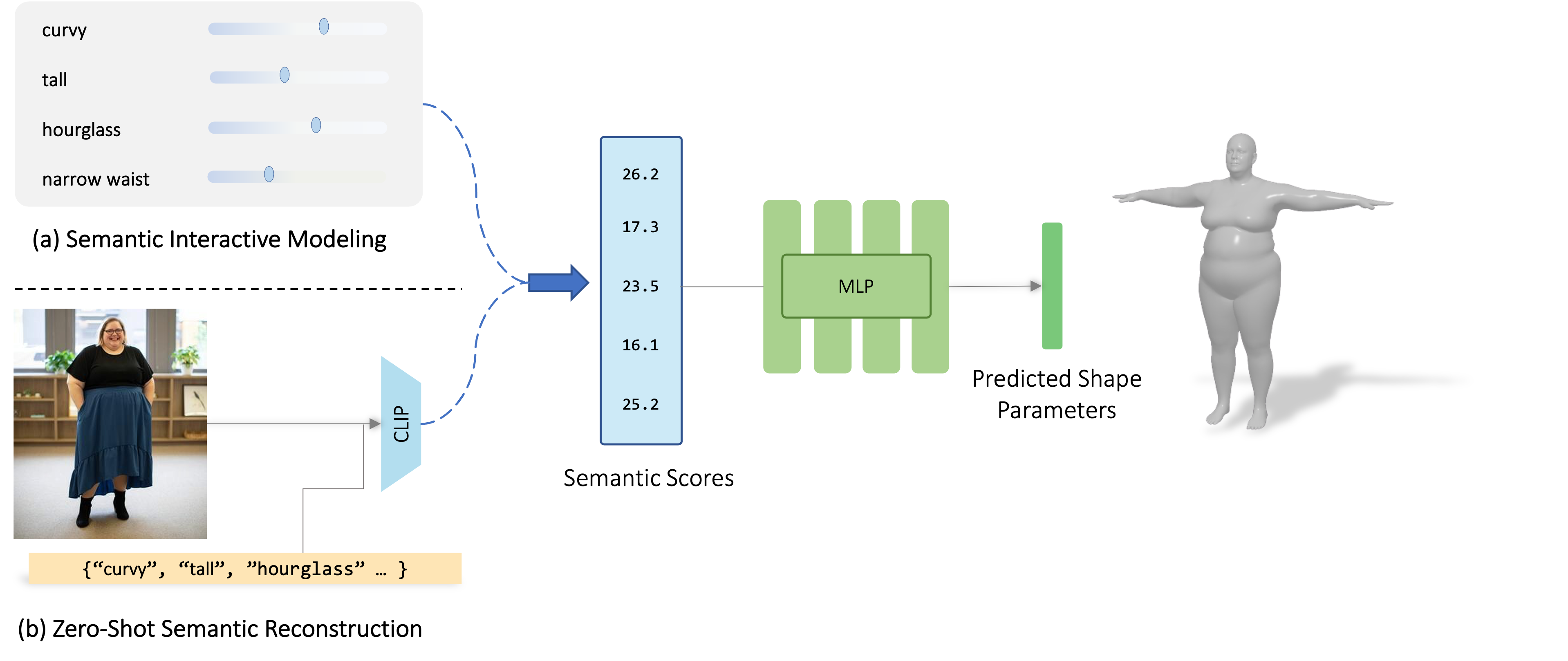
We present Semantify: a self-supervised method that utilizes the semantic power of CLIP language-vision foundation model to simplify the control of 3D morphable models.
Given a parametric model, training data is created by randomly sampling the model's parameters, creating various shapes and rendering them. The similarity between the output images and a set of word descriptors is calculated in CLIP's latent space. Our key idea is first to choose a small set of semantically meaningful and disentangled descriptors that characterize the 3DMM, and then learn a non-linear mapping from scores across this set to the parametric coefficients of the given 3DMM. The non-linear mapping is defined by training a neural network without a human-in-the-loop.
We present results on numerous 3DMMs: body shape models, face shape and expression models, as well as animal shapes. We demonstrate how our method defines a simple slider interface for intuitive modeling, and show how the mapping can be used to instantly fit a 3D parametric body shape to in-the-wild images.
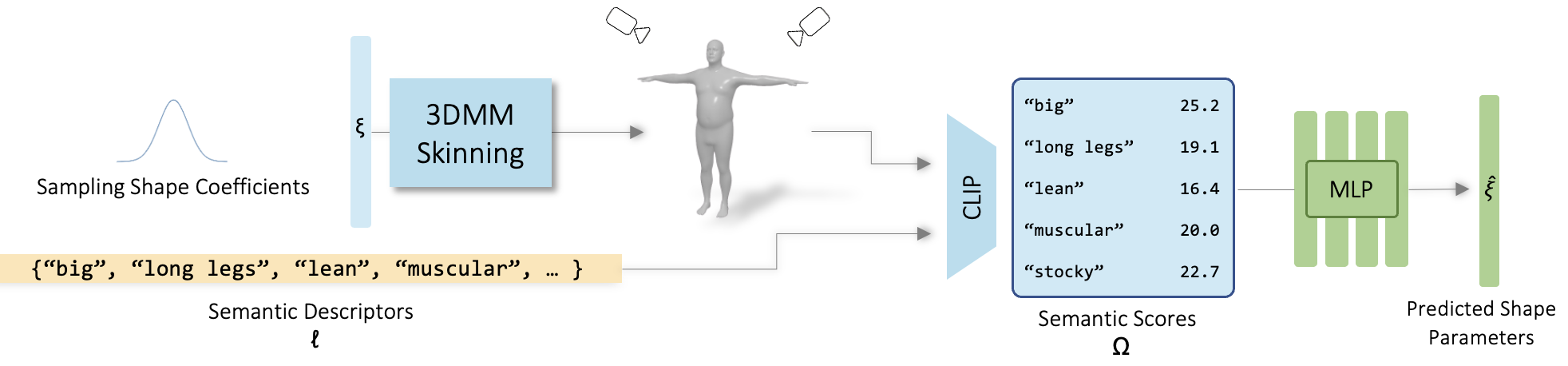
Learning a mapping from Semantic to Parametric space. (a) Given a coefficient vector ξ we create the 3DMM mesh. The mesh is rendered from several views. Each Rendered image I' is passed into CLIP along with a set of semantic descriptors ℓ. The difference between each descriptor and the image in CLIP latent space is calculated and stored in the corresponding entry of the similarity vector Ω. (b) Using a large set of such random pairs of (Ω,ξ), we train a network to learn the mapping from semantic space to parametric space.
Here we Visualize a subset of our Semantic change of basis, on some popular 3D Morphable models. Note: this applet is only an illustration and changes one axis at a time. It may take time to load so please wait until all models appear. To fully interact with our Semantic basis, we recommend using our code.
@InProceedings{Gralnik_2023_ICCV,
author = {Gralnik, Omer and Gafni, Guy and Shamir, Ariel},
title = {Semantify: Simplifying the Control of 3D Morphable Models Using CLIP},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2023},
pages = {14554-14564}
}